

Today, many of you might be using the latest AI tools and have come across ChatGPT. Most people are also using ChatGPT to make money. But how ChatGPT works? Which technique is used in the working of ChatGPT? How human feedback helps ChatGPt to produce more relevant results?
OpenAI has recently launched a new large language model, ChatGPT, which is an advanced member of the GPT-3 family. OpenAI ChatGPT uses the same methods that InstructGPT uses. But what makes ChatGPT unique? It is Reinforcement Learning that makes it different from older GPT-3.
ChatGPT works on Reinforcement Learning from Human Feedback (RLHF) to reduce harmful, false, and biased outputs through human feedback in the training loop. The developers of ChatGPT have combined two learning techniques: Supervised Learning and Reinforcement Learning, for fine-tuning ChatGPT.
Are you interested in knowing the working of ChatGPT? If yes, then you are at the right place. This article will provide a deep understanding of how ChatGPT works, what are the basics for the development of large language models, what are the shortcomings of GPT-3, and how ChatGPT overcomes them. Keep reading!
How ChatGPT Works?
ChatGPT is based on the methods used in InstructGPT. You can only see the difference in the setup of data collection.
OpenAI released its new AI tool, ChatGPT, on 30 November 2022. ChatGPT is known for building AI conversations. You can even integrate ChatGPT with Slack, Facebook, WhatsApp, WeChat, chatbot, your websites, and other platforms. If you are a banking professional you can easily use ChatGPT in banking.
Most of you might have used ChatGPT and wonder how this amazing tool works and produce accurate results within seconds.
To know how ChatGPT works, you must know the basic concept behind and large language model and drawbacks of GPT-3 before moving to the working of RLHF used by ChatGPT.
The following concepts will be discussed here to understand the complete working of ChatGPT:
- Large Language Model – Capability Vs Alignment
- Misalignments caused by language model training strategies
- ChatGPT works on Reinforcement Learning from Human Feedback (RLHF)
- ChatGPT – Performance evaluation
Let’s now discuss all these concepts in detail and learn the basic working mechanism of ChatGPT, including how human feedback helps to increase the performance of ChatGPT. Keep reading!
Large Language Model – Capability Vs Alignment
While talking about large language models, you must consider the model’s capability and alignment, as these are the most important factors for such models.
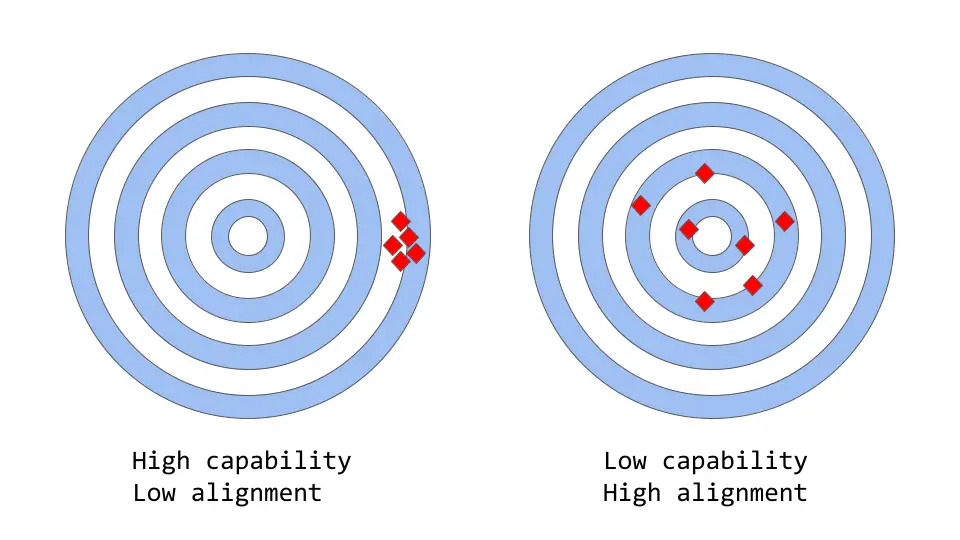
What are these terms in the context of machine learning? Here’s detailed information on the capability and alignment of the model:
Capability Of Large Language Model
The capability of the models refers to their ability to carry out a particular task or set of related tasks.
Let’s consider an example of a model used to predict any company’s stock price. If the model predicts the stock price accurately, then the model has a high capability for this task.
Alignment Of Large Language Model
The alignment of the language model is based on the actual task you want the model to perform and the task for which it is trained.
For example, if a model is trained to classify the material as “glass” or “wood,” log loss is used as the training objective, even though high accuracy is the goal.
Log loss calculates the difference between the true and predicted possibility distributions. The low log loss means that the model has the high capability but poor accuracy. In classifying the tasks, the log loss is not directly related to the accuracy.
As a result, there is a misalignment because the model can optimize the training objective but is not perfectly aligned with the ultimate objective. The GPT-3 model is misaligned, and this problem is solved in ChatGPT.
If you want to know more about how the misalignments are caused by the training strategies of the language models, then you must read the next section.
Misalignments Caused By Language Model Training Strategies
Before learning ChatGPT works on RLHF, one must know the limitations of GPT-3 and the misalignments that occur in GPT-3.
Even though the GPT-3 is trained on the vast textual data available on the internet to have human-like AI conversations, it does not always give the result according to human expectations. It leads to misalignment of the language model.
The misalignment of a model may be an issue for applications that demand a high level of trust or dependability, like conversational systems or intelligent personal assistants.
In large language models, the alignment issue typically occurs in the following forms:
- The model does not follow the user instructions accurately.
- Model hallucinates the inappropriate data and makes wrong facts.
- It is challenging for humans to comprehend how a model arrived at a specific conclusion or prediction.
- Even if it has not been explicitly instructed to do so, a language that has been trained on toxic data may produce that in the output.
Language models are trained on two basic techniques: Next token prediction and Masked language modeling.
Next Token Prediction
In the Next token prediction technique, as the name suggests, the model will predict the next word that will come in a given series of words as input.
Example: Input is given as “Table is made up of”
In this case, the model can predict the word “wood,” “glass,” or “plastic” because these are the probable words that will come next to the given sequence of text. These words have a high probability but may not be accurate according to human requirements.
The language model with Next token prediction can calculate the likelihood of each word from its vocabulary that will be next to the given sequence.
Masked Language Modeling
The Masked language modeling technique is the variation of the Next token prediction. In this technique, a special token, [MASK], is used in place of some of the words in the input sequence, and the model has to predict the appropriate word that will replace [MASK].
Example: Input is given as “The [MASK] is sitting on”
Here, the language model can predict the word “dog,” “parrot,” or “cat” in place of the mask.
Through this technique, the statistical structure of language, which includes frequent word sequences and usage patterns, can be learned by the language model. As it helps the model in generating more realistic and fluent text, this is the most crucial step in the pre-training process for language models.
Are you thinking that this problem has been solved in ChatGPT or not? Continue work has been carried out to remove this misalignment problem.
Researchers and developers have developed different strategies to solve the alignment issue in large language models.
ChatGPT working is based on the advanced GPT-3 family model. To minimize the model’s misalignment issues, ChatGPT works on the learning process which is achieved by using human feedback to train the GPT-3.5 version. This technique is termed Reinforcement Learning from Human Feedback (RLHF).
The news that this technique is first implemented in the production of the ChatGPT model will surely blow your mind.
The first question that strikes in mind after reading this is how ChatGPT works on Reinforcement Learning from Human Feedback. Let’s dive in to get the complete information on the working of ChatGPT!
How ChatGPT Works On Reinforcement Learning From Human Feedback (RLHF) Model?
ChatGPT works on the RLHF model, and the steps are, Supervised Fine-Tuning Model (SFT) > Reward Model (RM) > Proximal Policy Optimization Model (PPO).
OpenAI’s ChatGPT uses the Reinforcement Learning from Human Feedback (RLHF) model, which makes it unique from previously available GPTs. To learn how ChatGPT works, you must know that the ChatGPT model has three steps:
- Supervised Fine Tuning (SFT) Model
- Reward Model (RM) used to mimic human preferences
- PPO – Proximal Policy Optimization Model
Out of all the above steps, the first step of SFT occurs only once, but the other two are repeated. The data after comparison is collected from the PPO model, which is fed back to RM to train it and then forwarded to the new PPO model.
To understand all these steps in detail, keep reading through the below sections. It will help you to learn how ChatGPT works.
1. Supervised Fine Tuning Model – SFT Model In ChatGPT
The SFT model in ChatGPT works on, Data collection > Choosing a Model for pretraining.
The SFT model in ChatGPT is the baseline model. To understand the working of this supervised fine-tuning model, which utilizes a selected list of prompts to generate output, the labelers focus on the fine-tuning of a pre-trained language model based on a comparably small amount of demonstration data.
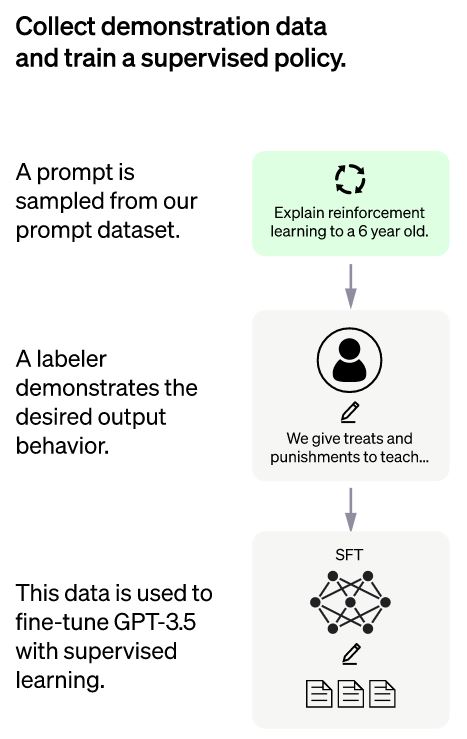
Here is the flowchart for the SFT model and the detailed explanation of all these steps covered in the working of the SFT model in ChatGPT are as follows:
Step 01: Collecting Demonstration Data
The first step of the SFT model is to collect demonstration data for training the supervised policy model. For data collection, ChatGPT uses two sources: data sampled from the API requests of OpenAI (the response from the GPT-3 users) and the developers or labelers. These human labelers give the expected output responses for the selected prompts list.
As the entire process is time-consuming and costly, the obtained result is a small, high-quality curated dataset (probably 12-15K data points). This result will be further used for fine-tuning the pre-trained language model.
Step 02: Choosing a Model for supervised learning
The developers of ChatGPT chose to fine-tune the pre-trained model in the GPT-3.5 series instead of choosing the previously used GPT-3. The code model of GPT was used instead of the pure text model to fine-tune the baseline model to create a ChatGPT bot.
The output obtained from this SFT model is still not much user-attentive and leads to misalignments because the dataset used here has limited data.
The only limitation of this supervised learning is that it is expensive to scale the SFT model. This limitation is overcome by allowing the labelers to rank the outputs generated by the SFT model instead of creating a larger dataset. This approach leads to the development of the Reward Model.
Let’s now see what is Reward Model (RM) and how it works.
2. Reward Model – RM In ChatGPT
Labelers rank the SFT model’s outputs to mimic human preferences based on the relevancy of the outputs for humans. A new dataset is created using this comparison data, and the new model, RM, is trained on this data set.
How does the Reward Model in ChatGPT works?
The flow of the Reward Model working in ChatGPT is Multiple outputs from the SFT model > Ranking the outputs > Data used to train RM.
The working of ChatGPT’s Reward Model starts from the outputs of SFT. The SFT model explained in the previous section generates multiple outputs for a single prompt from the list.
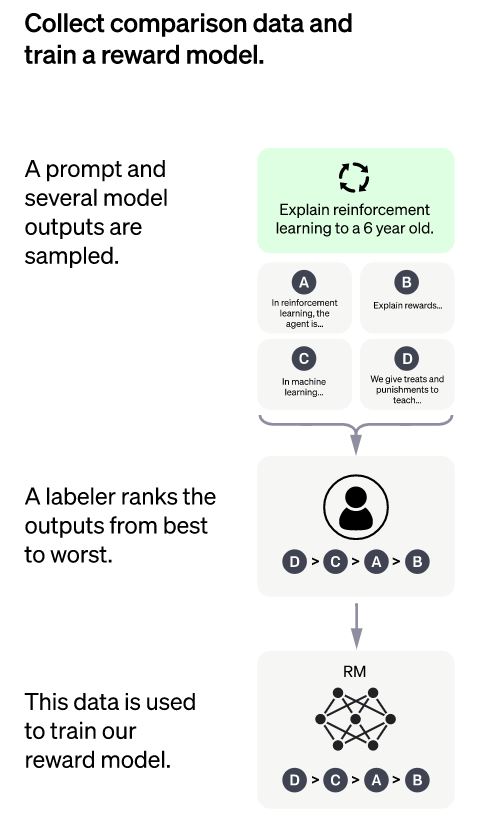
Now, have a look at what exactly happens in RM. The details of the workflow of the reward model shown in the above image are:
Step 01: Firstly, the multiple outputs from the SFT model are fed to the input of the RM.
Step 02: Now, the labelers assign the ranks (from best to worst) to these outputs of SFT.
Step 03: This ranking results in the formation of the new labeled dataset in which the ranks are referred to as labels. The labeled dataset is nearly 10 times larger than the curated dataset used in the SFT model.
Step 04: Finally, the new data obtained after ranking is used to train the Reward Model in ChatGPT.
It has been observed that it is easy to rank the outputs instead of generating the outputs from the start, and this technique increases the model’s efficiency.
Isn’t it amazing that this dataset is created using the 30-40K prompts? It is known that the dataset generated after the ranking phase will be ten times this huge set of data. Imagine how large will be the new dataset which is further used for training RM in ChatGPT.
You might be thinking about the next step after Reward Model and how it is further used to get the optimized final results. Continue reading the next section to learn about the optimization model and the fine-tuning of the SFT model using PPO.
3. Proximal Policy Optimization Model – Using PPO To Fine-Tune SFT Model
The working of the PPO model in ChatGPT is based on the value function, and the SFT and Reward Model initialize the policy model. The whole environment is based on probability and machine learning which gives the expected response to the random prompt.
What is the Policy Model in ChatGPT? The Policy Model is the output generated when the Reward Model is used to improve and fine-tune the SFT model.
You might have heard about Reinforcement learning. It is a learning stage where the software interacts with the environment and receives rewards or punishments for different tasks. From this, the software learns to produce more accurate results and improves its performance.
Proximal Policy Optimization is an algorithm used for training the ChatGPT through reinforcement learning.
Here are some facts about the optimization method, PPO:
- PPO adapts the current policy and is also called the ‘on-policy’ algorithm because it utilizes user action and human feedback to train the model.
- The optimization method used in PPO is the trust-region method. To ensure stability, the changes in the policy must be done within a certain distance from the old policy.
- PPO uses a ‘Value function’ to calculate the anticipated output of a command or action.
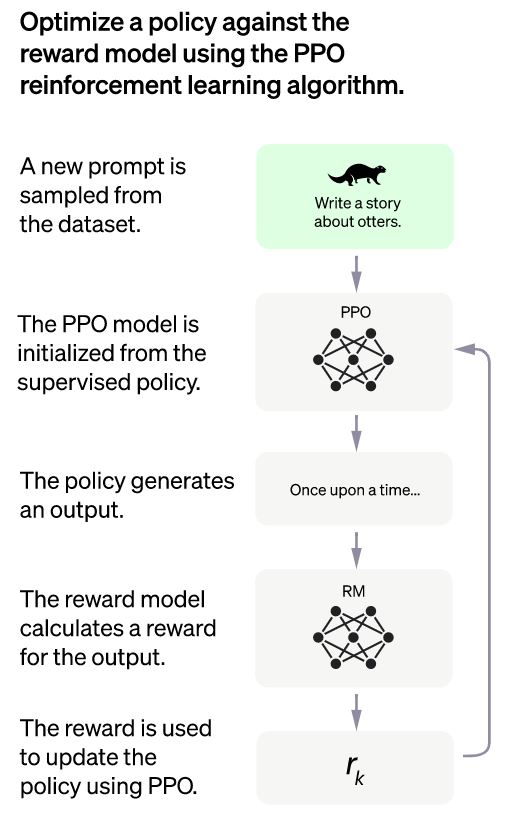
But how this value function in the PPO of ChatGPT works? You can see how the PPO model in ChatGPT works from the above image showing the flowchart of the optimization policy.
The following steps are covered in the working of the value function used by the PPO model:
Step 01: The value function calculates the advantage function, which reflects the difference between the expected and the current result.
Step 02: Now, the advantage function updates the policy by comparing the previous and current policies’ actions.
Step 03: Finally, the policy is updated with more accurate results by considering the estimated values of the actions.
This is all that you need to know about the Proximal Policy Optimization used for fine-tuning the SFT model (Supervised Fine Tuning). The process is the PPO, Proximal Policy Optimization, and the final fine-tuned model is known as PPO Model.
ChatGPT – Performance Evaluation
The final activity to do is evaluating the performance of ChatGPT. As the model’s training is based on the rating given by the human labelers to the quality of the outputs produced, the most important part of the performance evaluation is based on human input.
The test set uses the prompts from OpenAI users who have stalled but are not defined in the training data to avoid overfitting to the labeler’s judgment who took part in the training phase.
The criteria on which the ChatGPT model is evaluated are:
- Helpfulness: The model’s ability is evaluated based on how it follows the instructions given by the user and figures them out.
- Truthfulness: The model’s truthfulness is checked on the TruthfulQA dataset. The model’s tendency to make facts is judged when performing closed-domain tasks.
- Harmlessness: The labelers evaluate the performance of the model’s output to determine whether it is appropriate, diminishes protected class, or contains offensive content.
- Zero-shot performance: The standard AI tasks, such as question answers, summarizing, and reading comprehension, are evaluated for zero-show performance.
When training the PPO model using gradient descent, the gradient updates are calculated by combining the gradients of SFT and PPO models. This method is known as the Pre-train mix, and it effectively reduces performance relapses on these datasets.
That’s all about how ChatGPT works on the Reinforcement Learning from Human Feedback (RLHF) Model. All the steps, including the performance evaluation, have been covered.
Wrapping Up
Researchers are continuously working to improve the working of AI models by removing the issues of older GPT versions. ChatGPT works on the advanced member of the GPT-3 family and human feedback. You might be thinking about how ChatGPT works and has the alignment issue of GPT-3 removed from it.
This article covers all the insights into the ChatGPT works starting from the basic concepts involved in the large language models and the misalignment issue to the ChatGPT pre-training models. Well, this will not stop here, OpenAI is soon going to release GPT-4. Follow Deasilex to get more information on AI technologies.
Frequently Asked Questions
Q. How Does ChatGPT Work?
ChatGPT works on the top GPT-3 family member, i.e. GPT-3.5, and is trained to work on the learning process using human feedback. With ChatGPT you can talk to language models by asking questions.
Q. How To Use ChatGPT?
To use ChatGPT, go to OpenAI ChatGPT website > Login or Sign Up using your Microsoft or Google account or your email address > New Chat > Type what you want to ask to the ChatGPT chatbot > See the answer to your question > Save the AI conversation.
Q. What Is ChatGPT?
ChatGPT is a chatbot that had been launched by OpenAI in 2022 November ending. GPT stands for Generative Pretrained Transformer. It works on natural language processing (NLP) and is responsible for producing realistic AI conversations.