
The launch of the new TTS tool, VALL-E, has made the public think about what is VALL-E. You might be wondering about the Microsoft VALL-E workings and the architecture of the VALL-E framework.
Microsoft’s VALL-E is recently launched after other AI tools like DALL-E, Point-E, and Google Imagen. The Microsoft VALL-E is the next-generation text-to-speech tool. VALL-E has many features, mainly the diversity and the maintenance of the speaker’s tone. But what about the Microsoft VALL-E workings?
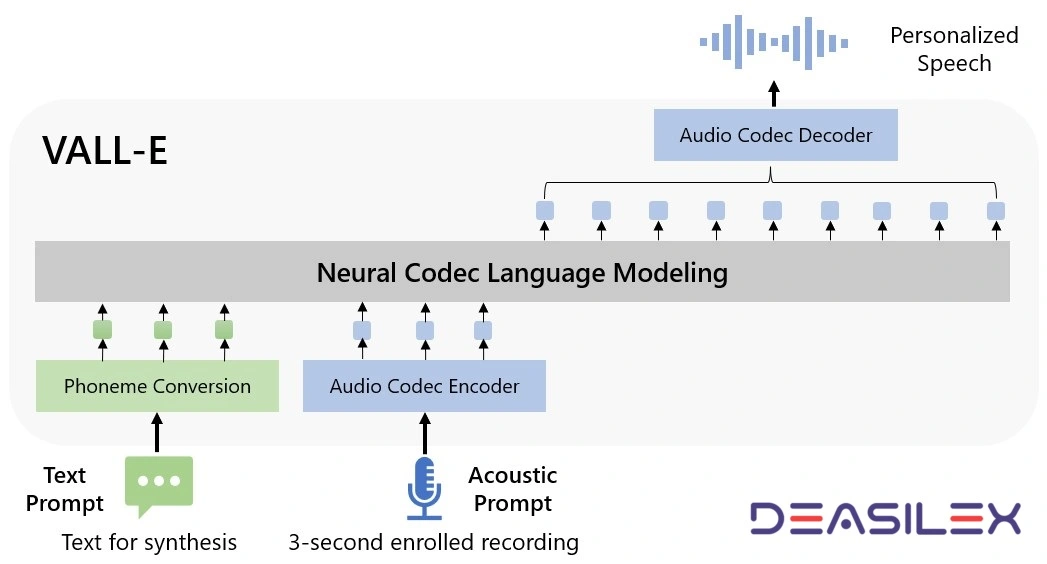
When it comes to the Microsoft VALL-E workings, the basic principle of VALL-E is neural codec language modeling. The architecture of VALL-E shows that the Phoneme Conversation and Audio Codec Encoder results are sent to the language model, which generates the discrete code. At last, the Audio Codec Decoder is used to convert the signal into the waveform.
Are you amazed by the new text-to-speech tool, VALL-E, launched by Microsoft? You might be eager to know about the Microsoft VALL-E workings. This article will provide you with the architecture of VALL-E framework and the working of Microsoft VALL-E. Keep reading!
What Is VALL-E?
What is VALL-E? VALL-E is the advanced model for text-to-speech synthesis designed by Microsoft. It is not publicly available for use as it is under development, but the research done till now is out.
If you are a researcher and want to know more details about the VALL-E, the next-generation text-to-speech tool, you must read the research paper on VALL-E, which contains all the insights of the new emerging TTS framework.
VALL-E is a language model technique used for TTS synthesis. This Microsoft VALL-E model uses the audio recording as the reference for voice tone. With just a short 3-second recording and a text prompt, a synthesized speech is generated, maintaining the speaker’s emotional voice.
You will be able to generate the speech outputs in different tones with the same input text but different input audio recordings. This is possible because of the tone used in the recording, as the output tone depends on this 3-second recording.
Till now, you might be using Google text-to-speech, but with the launch of VALL-E, you will prefer it. You can also find the major differences between Google text-to-speech and VALL-E, which makes Microsoft VALL E applicable in more areas.
The results from the VALL-E are more accurate than any other text-to-speech technique as it has been trained on TTS data of over 60 thousand hours which is much larger than the current models. Many VALL-E use cases came out after knowing its features, architecture, and working.
Let’s now move to the next section on Microsoft VALL-E workings. It will cover the architecture of VALL-E framework and the working of VALL-E.
Microsoft VALL-E Workings
In Microsoft VALL-E workings, the steps for signal synthesis include, Text prompt fed to Phoneme Conversation > Acoustic prompt fed to Audio Codec Encoder > Signals from Phoneme Conversation and Audio Codec Encoder to Neural Codec Language Modelling > Discrete output signal to Audio Codec Decoder > Output signal.
What is the working of Microsoft VALL-E? Before knowing the Microsoft VALL-E workings, you must know that Microsoft VALL-E works on neural codec language modeling for text-to-speech (TTS) synthesis.
In short, by using the VALL-E, you can generate the voice file by changing the wording according to your input text by maintaining the speaker’s tone. This is one of the best features of the Microsoft VALL-E.
The Microsoft VALL-E produces the discrete audio codes by combining the phoneme signal and text prompt using the Neural Codec language modeling technique. The output signal is generated based on the text prompt and the speaker’s tone.
The components used in the Microsoft VALL-E framework are:
- Text Prompt
- Phoneme Conversation
- Acoustic Prompt (3-second voice recording)
- Audio Codec Encoder
- Neural Codec Language Modelling
- Audio Codec Decoder
Now, to understand the detailed Microsoft VALL-E workings, you must refer to the architecture of VALL-E framework shown at the start of the article. In the figure, you can find that the phoneme prompt and the acoustic tokens of the 3-second enrolled voice recording, which confines the speaker and content information, respectively, are used by VALL-E to generate the associated acoustic tokens for individualized speech synthesis (e.g., zero-shot TTS).
The output from the neural audio codec model is in the form of discrete acoustic tokens. The text-to-speech system is thus considered as conditional codec language modeling because of these discrete audio tokens. The final waveform is created using the generated acoustic tokens and the appropriate audio codec decoder.
The TTS activities can be benefited from the large model techniques based on advanced prompting (as used in GPTs). The acoustic tokens also provide distinct synthesized outputs in TTS by utilizing various sampling techniques during inference.
If you want to understand the Microsoft VALL-E workings in simple words, you must check the next section. Continue reading!
Microsoft VALL-E Workings Explained
In other words, the speech synthesis process of the Microsoft VALL-E workings starts when you input a 3 seconds voice recording to the audio encoder and a text prompt to the phoneme conversation. The text must be the wording you want in the output speech, whereas the voice recording is for the tone of the speaker.
Now, the outputs from this encoder and phoneme are the input of the codec language model, which finally combines both the voice and the text signals. The model generates the speech signal in a discrete form. So, finally, to get an audible signal, the decoder is used to convert the discrete signal to a waveform.
The final output signal generated will be the synthesized speech signal in which the wordings will be the same as you entered in the text prompt, but the speaker’s voice tone will be the same as the 3 second recording.
Isn’t it amazing? Why wait if you are more into using TTS tools, go and download the Microsoft VALL-E to enjoy its available demos/samples.
Wrapping Up
Microsoft VALL-E is a new language model for speech synthesis, a text-to-speech system. VALL-E will help the people who have lost their voice and will be more useful in more fields in the future. If you are looking for the Microsoft VALL-E workings, then this article will help you to understand the principle working of VALL-E.
The architecture of the VALL-E framework explains the complete flowchart of the model. The Microsoft VALL-E workings explained cover the functioning of each component used in the model. Follow Deasilex to learn more about this new evolving text-to-speech and AI technologies!
Frequently Asked Questions
Q. What Is The Working Pipeline of VALL-E?
The working pipeline of VALL-E is Phoneme Conversation – Discrete Code – Waveform.
Q. The VALL-E Maintains Which Emotions Of The Speaker?
Microsoft VALL-E maintains the five emotions of speakers, which are as follows:
Anger
Sleepy
Disgusted
Amused
Neutral
Q. What Are The Microsoft VALL-E Applications?
In the future, the Microsoft VALL-E can be applied to a variety of speech synthesis tasks, such as zero-shot TTS, speech editing, and content creation, when combined with other AI models like GPT-3. But, the likelihood of receiving false calls rises when Microsoft VALL-E is used.